Linguistic analysis of who wrote the op-ed
David Robinson did a nice writeup of using his R package to analyze who wrote the “I Am Part of the Resistance Inside the Trump Administration” op-ed in NYTimes. His approach was with TF-IDF of the words.
I wanted to try this with different text statsistics of the linguistic features instead, since I’m guessing word usage will not give the author away. And in Python of course.
import spacy
import re
import pandas as pd
import numpy as np
from textstat.textstat import textstat
from twitter_scraper import get_tweets
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 180
from spacy.attrs import ORTH
pd.options.display.max_columns = 999
pd.options.display.max_rows = 999
nlp = spacy.load('en')
article_text = "President Trump is facing a test to his presidency unlike any faced by a modern American leader. It’s not just that the special counsel looms large. Or that the country is bitterly divided over Mr. Trump’s leadership. Or even that his party might well lose the House to an opposition hellbent on his downfall. The dilemma — which he does not fully grasp — is that many of the senior officials in his own administration are working diligently from within to frustrate parts of his agenda and his worst inclinations. I would know. I am one of them. To be clear, ours is not the popular “resistance” of the left. We want the administration to succeed and think that many of its policies have already made America safer and more prosperous. But we believe our first duty is to this country, and the president continues to act in a manner that is detrimental to the health of our republic. That is why many Trump appointees have vowed to do what we can to preserve our democratic institutions while thwarting Mr. Trump’s more misguided impulses until he is out of office. The root of the problem is the president’s amorality. Anyone who works with him knows he is not moored to any discernible first principles that guide his decision making. Although he was elected as a Republican, the president shows little affinity for ideals long espoused by conservatives: free minds, free markets and free people. At best, he has invoked these ideals in scripted settings. At worst, he has attacked them outright. In addition to his mass-marketing of the notion that the press is the “enemy of the people,” President Trump’s impulses are generally anti-trade and anti-democratic. Don’t get me wrong. There are bright spots that the near-ceaseless negative coverage of the administration fails to capture: effective deregulation, historic tax reform, a more robust military and more. But these successes have come despite — not because of — the president’s leadership style, which is impetuous, adversarial, petty and ineffective. From the White House to executive branch departments and agencies, senior officials will privately admit their daily disbelief at the commander in chief’s comments and actions. Most are working to insulate their operations from his whims. Meetings with him veer off topic and off the rails, he engages in repetitive rants, and his impulsiveness results in half-baked, ill-informed and occasionally reckless decisions that have to be walked back. “There is literally no telling whether he might change his mind from one minute to the next,” a top official complained to me recently, exasperated by an Oval Office meeting at which the president flip-flopped on a major policy decision he’d made only a week earlier. EDITORS’ PICKS The Flourishing Business of Fake YouTube Views The Iraqi Spy Who Infiltrated ISIS What Happens to #MeToo When a Feminist Is the Accused? The erratic behavior would be more concerning if it weren’t for unsung heroes in and around the White House. Some of his aides have been cast as villains by the media. But in private, they have gone to great lengths to keep bad decisions contained to the West Wing, though they are clearly not always successful. It may be cold comfort in this chaotic era, but Americans should know that there are adults in the room. We fully recognize what is happening. And we are trying to do what’s right even when Donald Trump won’t. The result is a two-track presidency. Take foreign policy: In public and in private, President Trump shows a preference for autocrats and dictators, such as President Vladimir Putin of Russia and North Korea’s leader, Kim Jong-un, and displays little genuine appreciation for the ties that bind us to allied, like-minded nations. Astute observers have noted, though, that the rest of the administration is operating on another track, one where countries like Russia are called out for meddling and punished accordingly, and where allies around the world are engaged as peers rather than ridiculed as rivals. On Russia, for instance, the president was reluctant to expel so many of Mr. Putin’s spies as punishment for the poisoning of a former Russian spy in Britain. He complained for weeks about senior staff members letting him get boxed into further confrontation with Russia, and he expressed frustration that the United States continued to impose sanctions on the country for its malign behavior. But his national security team knew better — such actions had to be taken, to hold Moscow accountable. This isn’t the work of the so-called deep state. It’s the work of the steady state. Given the instability many witnessed, there were early whispers within the cabinet of invoking the 25th Amendment, which would start a complex process for removing the president. But no one wanted to precipitate a constitutional crisis. So we will do what we can to steer the administration in the right direction until — one way or another — it’s over. The bigger concern is not what Mr. Trump has done to the presidency but rather what we as a nation have allowed him to do to us. We have sunk low with him and allowed our discourse to be stripped of civility. Senator John McCain put it best in his farewell letter. All Americans should heed his words and break free of the tribalism trap, with the high aim of uniting through our shared values and love of this great nation."
Here’s a function that takes a arbritary text, and calculates various text statistics. Stuff like mean sentence lenght, variance in sentence lenght, different text difficulty measures from the textstat package. And of course the usage of how much different part of speech is present through the package Spacy.
def linguistic_features(text):
""" Takes a text as input and returns various linguistic features of it """
doc = nlp(text)
# Some standard statistics
sent_lens = [len(s) for s in doc.sents]
mean_sentence_length = np.mean(sent_lens)
sentence_std = np.std(sent_lens)
counts = doc.count_by(ORTH)
n_sentences = len(list(doc.sents))
def per_sentence(char):
""" Count occurances and divide by number of sentences """
try:
return counts[doc.vocab.strings[char]] / n_sentences
except KeyError:
return 0.0
all_caps_count = 0
pos_counts = {}
for token in doc:
# Count capitalized words
if token.text.isupper():
all_caps_count += 1
# Collect POS statistics
try:
pos_counts[token.pos_] += 1
except KeyError:
pos_counts[token.pos_] = 1
pos_per_sent = {f'{k}_per_sent': v / n_sentences for k, v in pos_counts.items()}
return {
'flesch_reading_ease': textstat.flesch_reading_ease(text),
'smog_index': textstat.smog_index(text),
'flesch_kincaid_grade': textstat.flesch_kincaid_grade(text),
'coleman_liau_index': textstat.coleman_liau_index(text),
'dale_chall_readability_score': textstat.dale_chall_readability_score(text),
'difficult_words_per_sent': textstat.difficult_words(text) / n_sentences,
'linsear_write_formula': textstat.linsear_write_formula(text),
'dots_per_sent': per_sentence('.'),
'commas_per_sent': per_sentence(','),
'colons_per_sent': per_sentence(':'),
'bindings_per_sent': per_sentence('-'),
'long_bindings_per_sent': per_sentence('–'),
'quotes_per_sent': per_sentence('"'),
'questions_per_sent': per_sentence('?'),
'exclamations_per_sent': per_sentence('!'),
'mean_sentence_length': mean_sentence_length,
'sentence_std': sentence_std,
'uppercase_words_per_sent': all_caps_count / n_sentences,
**pos_per_sent
}
In lack of time to find good text samples of the White House officials I’ve used their Twitter accounts. This is of course a stretch since there’s no guarrantees that the style you use on Twitter would match the style you use when writing an op-ed. But maybe, just maybe it matches enough?
# List of White House officials twitter accounts to examine
wh_officials = [
'TomBossert45',
'jdgreenblatt45',
'VPComDir',
'SecPompeo',
'RajShah45',
'SecAzar',
'SecNielsen',
'USTradeRep',
'SecretarySonny',
'SecretaryRoss',
'OMBPress',
'EPAAWheeler',
'SecShulkin',
'SecretaryPerry',
'SecPriceMD',
'BetsyDeVosED',
'SecretaryCarson',
'SecretaryZinke',
'SecElaineChao',
'POTUS',
'SBALinda',
'SecretaryAcosta',
'Cabinet',
'VP',
'stevenmnuchin1',
'nikkihaley',
'realDonaldTrump',
'mike_pence',
'sendancoats',
'PressSec',
'GeneralJohnK',
'KellyannePolls',
'StephenMoore'
]
We don’t need the urls.
def remove_urls(t):
return re.sub(r'https?:\/\/.*[\r\n]*', '', t, flags=re.MULTILINE)
Let’s take a twitter accounts collected text and chunk it. That way we can see if the similiarity is consistent by boostrapping some sort of confidence of the similarity.
def collect(user):
""" Collect text from twitter account """
dump = ""
for tweet in get_tweets(user, pages=50):
try:
dump += ' ' + remove_urls(tweet['text'])
except:
continue
return dump
def chunk(in_string, num_chunks):
""" Chunk a string onto `num_chunks` of equal size """
chunk_size = len(in_string) // num_chunks
if len(in_string) % num_chunks: chunk_size += 1
iterator = iter(in_string)
for _ in range(num_chunks):
accumulator = list()
for _ in range(chunk_size):
try: accumulator.append(next(iterator))
except StopIteration: break
yield ''.join(accumulator)
Now we are ready to collect and calculate all the statistics.
data = {}
for o in wh_officials:
print(o)
text = collect(o)
parts = list(chunk(text, 10))
data[o + '_1'] = linguistic_features(parts[0])
data[o + '_2'] = linguistic_features(parts[1])
data[o + '_3'] = linguistic_features(parts[2])
data[o + '_4'] = linguistic_features(parts[3])
data['article'] = linguistic_features(article_text)
df = pd.DataFrame.from_dict(data, orient='index').fillna(0.0)
There are many similarity measures but here, after min-max normalizing the features – I use cosine distance.
similarities = (
pd.DataFrame(
# Cosine similarity of min-max normalized df
cosine_similarity((df - df.min()) / (df.max() - df.min())),
index=df.index,
columns=df.index
)[['article']]
.query('index != "article"')
)
ax = sns.barplot(
y="index", x="article",
data=(
similarities.reset_index()
.assign(index=lambda r: r['index'].str.split('_').str[0:-1].str.join('_'))
),
order=(
similarities.reset_index()
.assign(index=lambda r: r['index'].str.split('_').str[0:-1].str.join('_'))
.groupby('index').median()
.reset_index()
.sort_values('article')
)['index']
)
ax.set(xlabel='Similarity to article style', ylabel='')
sns.despine()
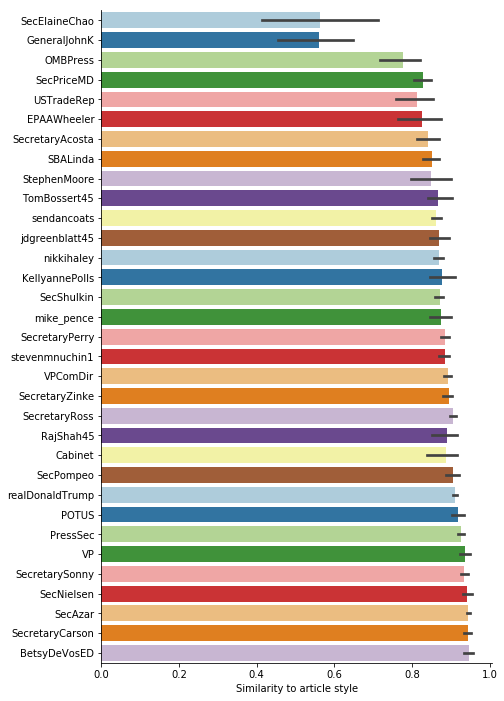
Dropping out of this is that most similar are BetsyDeVosED, SecretaryCarson, SecAzar, SecNielsen, SecretarySonny, and VP Pence. I have no idea if this anywhere near the truth of course. As far as I’ve read, the only name of those that have been speculated is Pence.